Project Summary: The interest in Privacy Preserving technologies has increased in recent years, and it is now making its way to private and public sector applications that use private data. Similarly, the increased usage of Machine Learning (ML) in many applications requires big datasets that are not easily accessible for individual companies or handled by different departments in those organizations. A good solution to this challenge of training on distributed datasets is Federated Learning (FL). It allows organizations or governments to collaborate in training ML models without sending raw data. This helps train more robust ML models from localized data but does not prevent attacks on the models generated from such data.
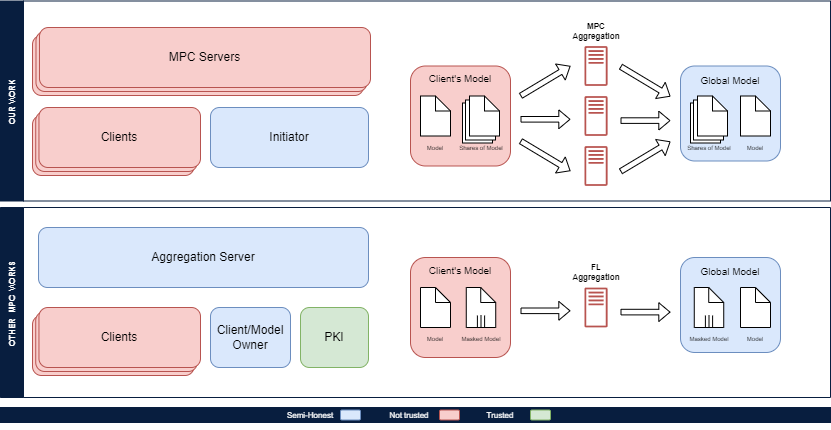
While there are several privacy-preserving technologies used to protect the models like Multiparty Computation (MPC), Fully Homomorphic Encryption (FHE), and Differential Privacy (DP), we propose using MPC to enable a comprehensive service for FL. The reason is that MPC offers higher security guarantees, while not compromising the accuracy of the models or using an excessive amount of hardware resources. Additionally, we can run the aggregation phase of FL in a dishonest majority setting (i.e., the majority of the parties are not trusted), while keeping our model distributed among the participating MPC parties. While the model is distributed, the MPC protocol allows us to perform a range of complex operations on the model without revealing any details about it.
We propose a system model that takes advantage of the distributed nature of MPC to help train on highly sensitive data such as government-collected data or user-collected data (e.g., health records). Our aim with this system is to conduct training on dishonest majority networks while utilizing the least amount of resources possible.
This work is supported in part by US National Science Foundation and AFRL.
People: Richard Hernandez, Oscar Bautista, Dr. Mohammad Hossein Manshaei, and Dr. Kemal Akkaya
Publications: [None]